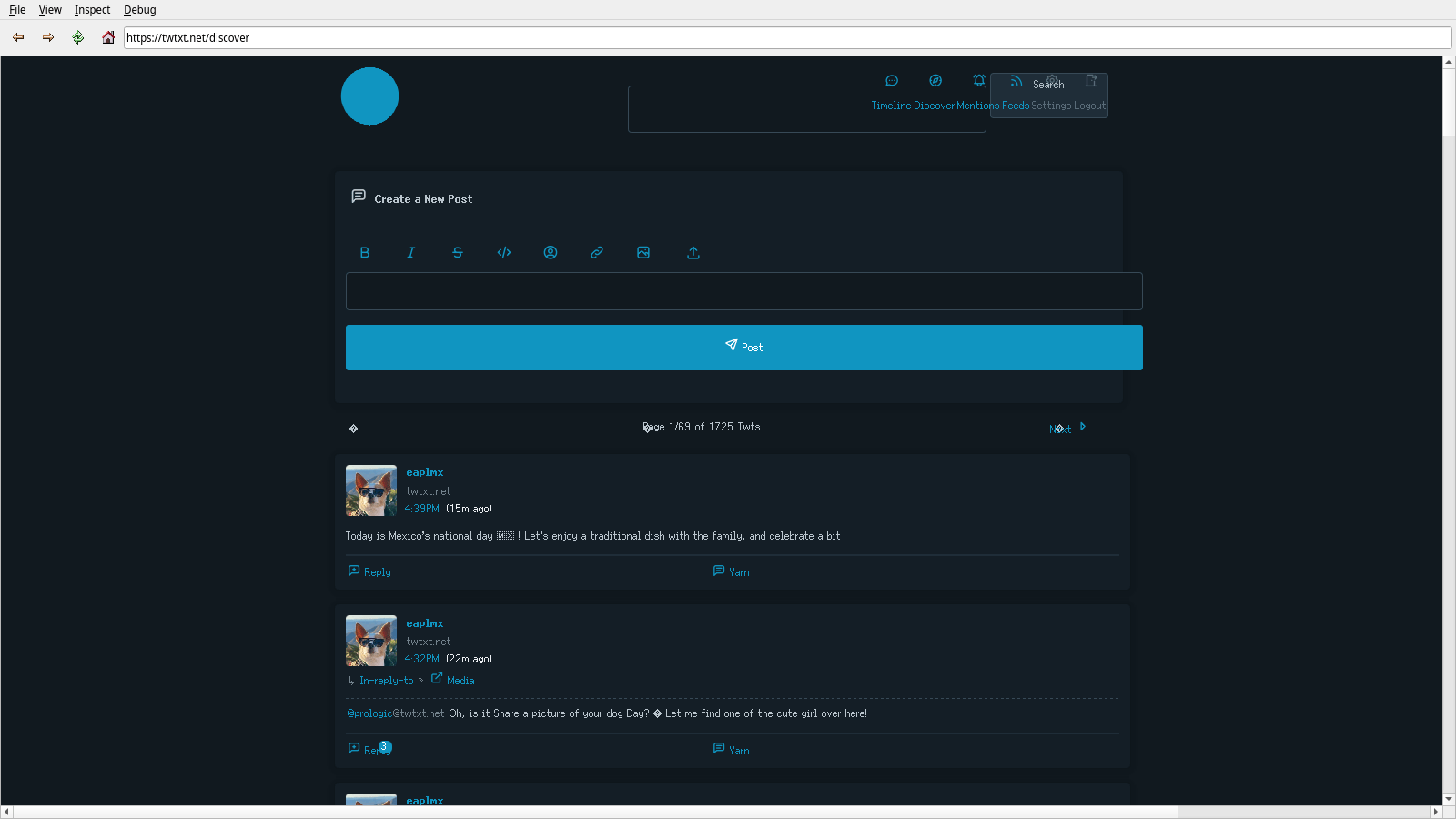
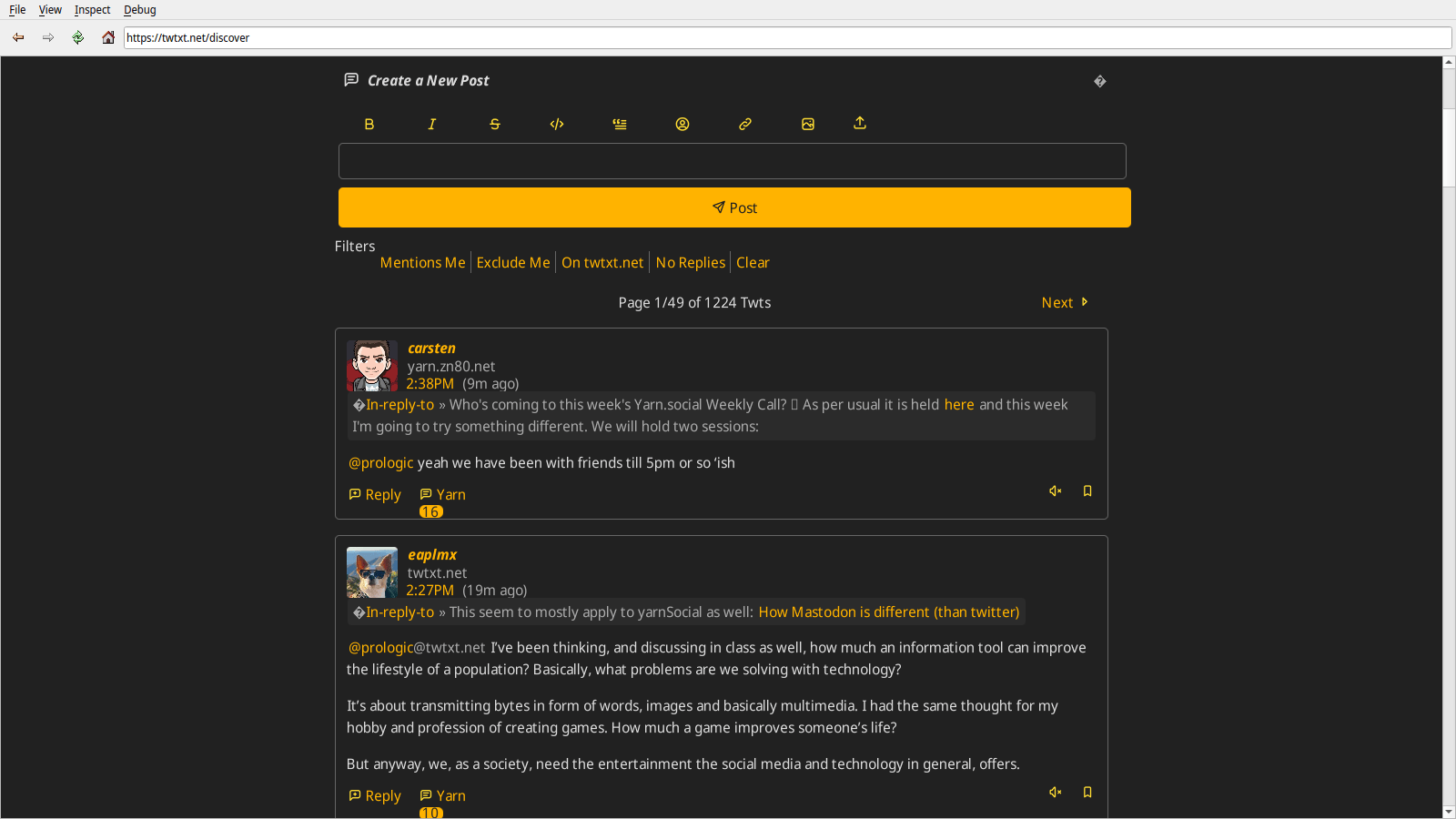
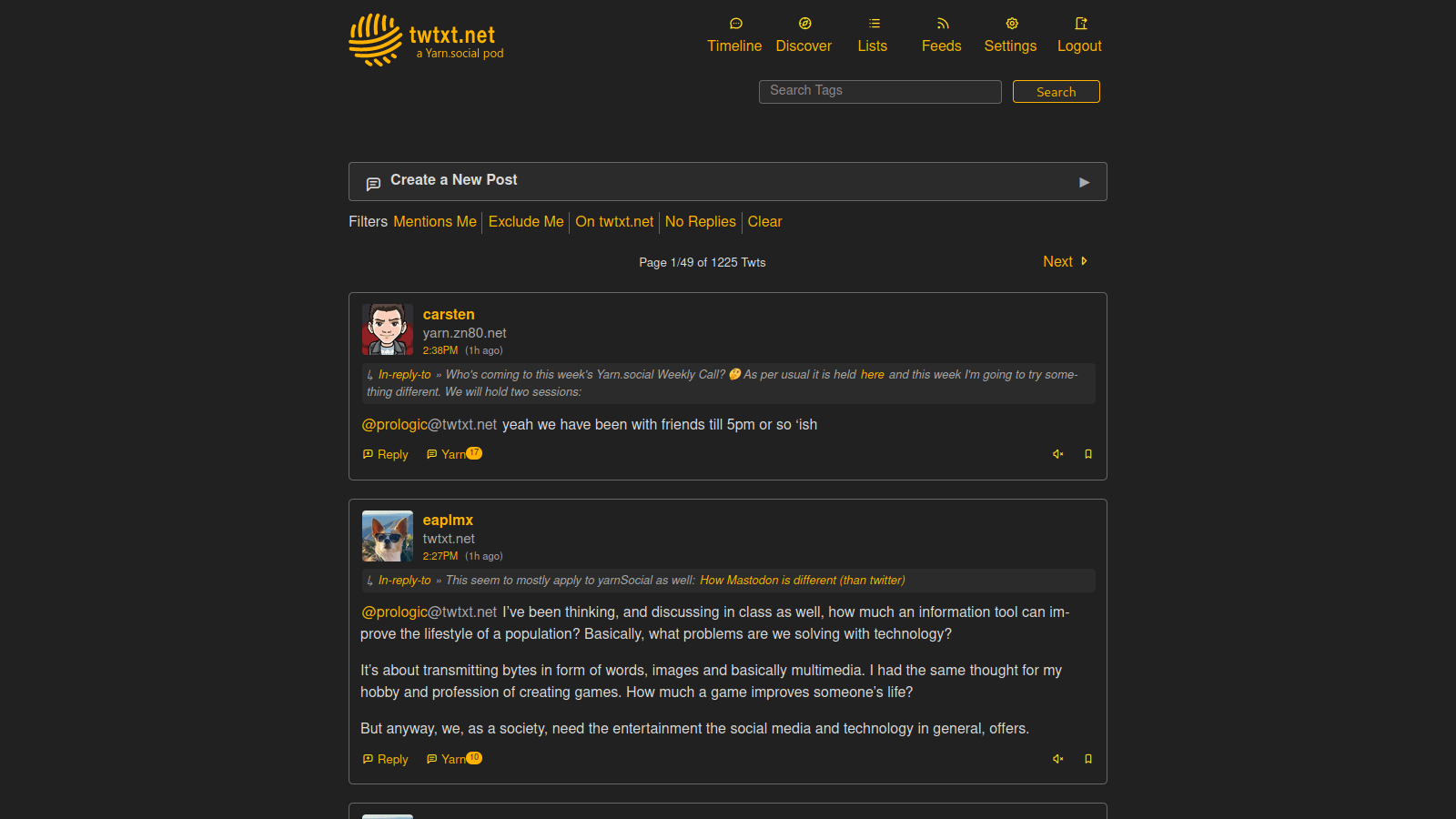
It was nearly 6 months ago when I last took a look at the Ladybird browser's rendering of Yarn.social's Discover page. This is where we are in 2023. Note that this is only looking at Ladybird's progress in rendering one particular Web service which changes over time. It's not representative of total progress overall.
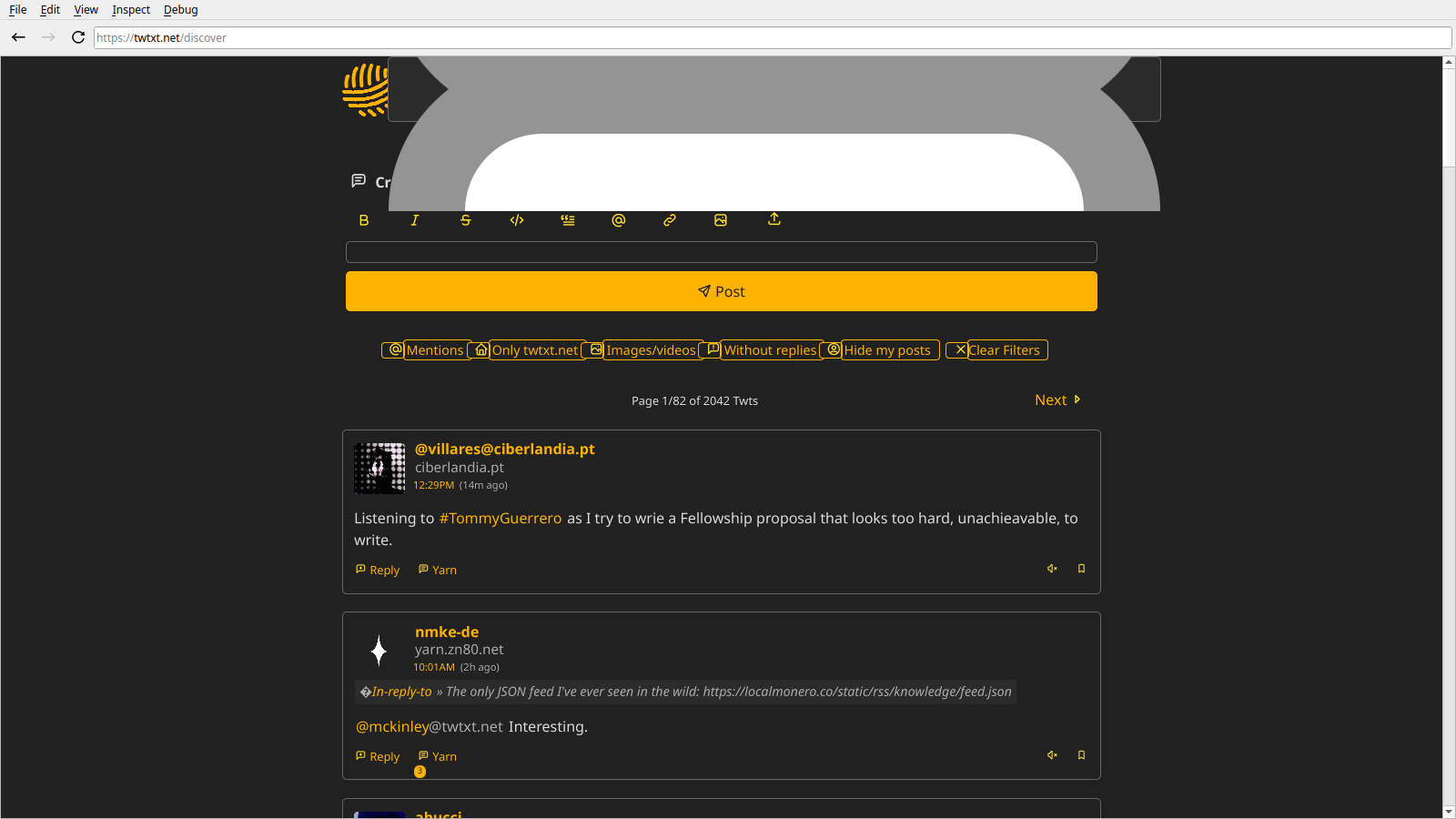
Of course, the elephant in the room is the giant white and gray thing at the top of the page. I wasn't able to find the cause of this, but I imagine it has something to do with poor handling of the icons at the top of the page. I can say that the developer tools have vastly improved in the last 6 months, though there are some stability problems with them.
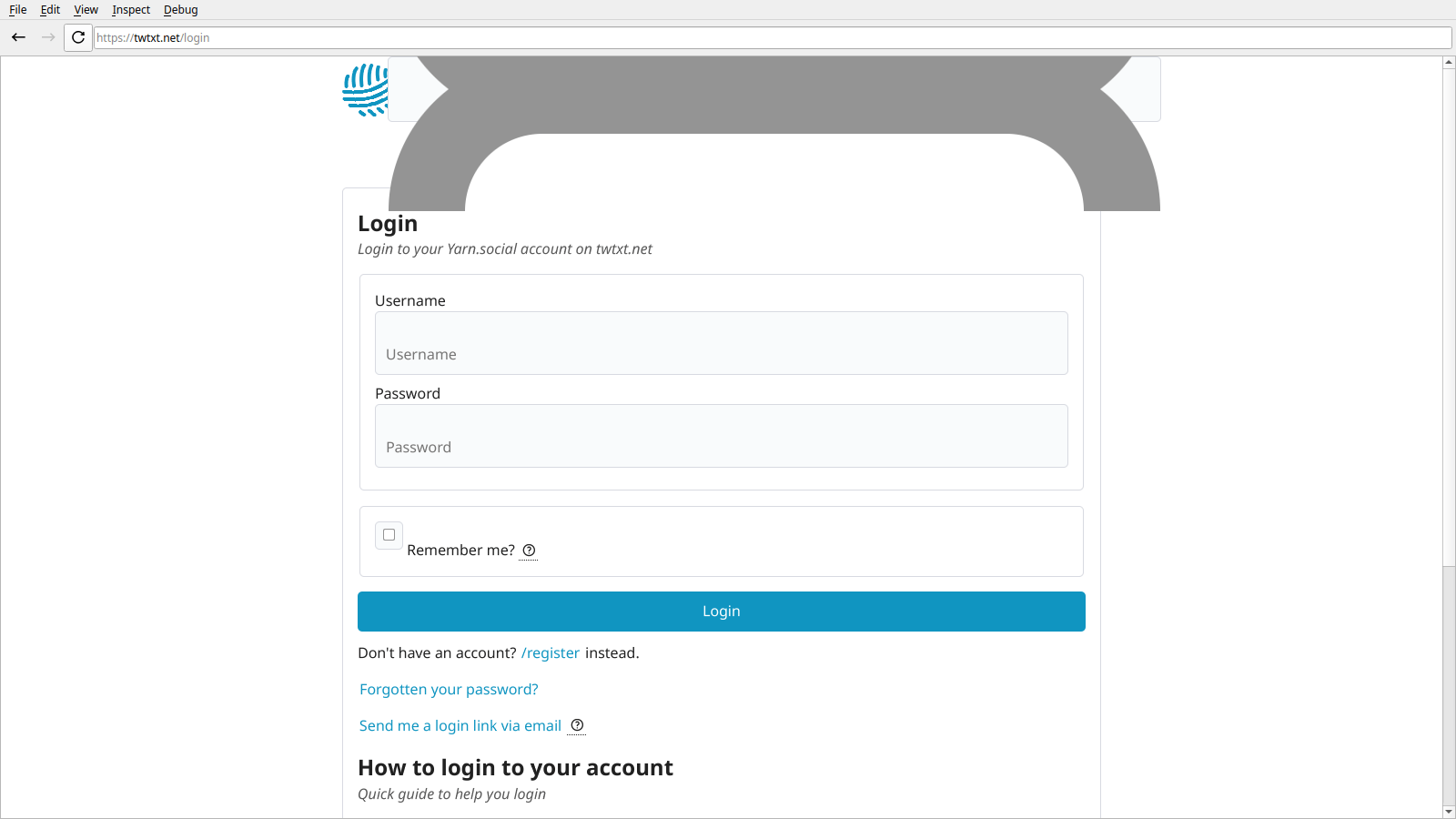
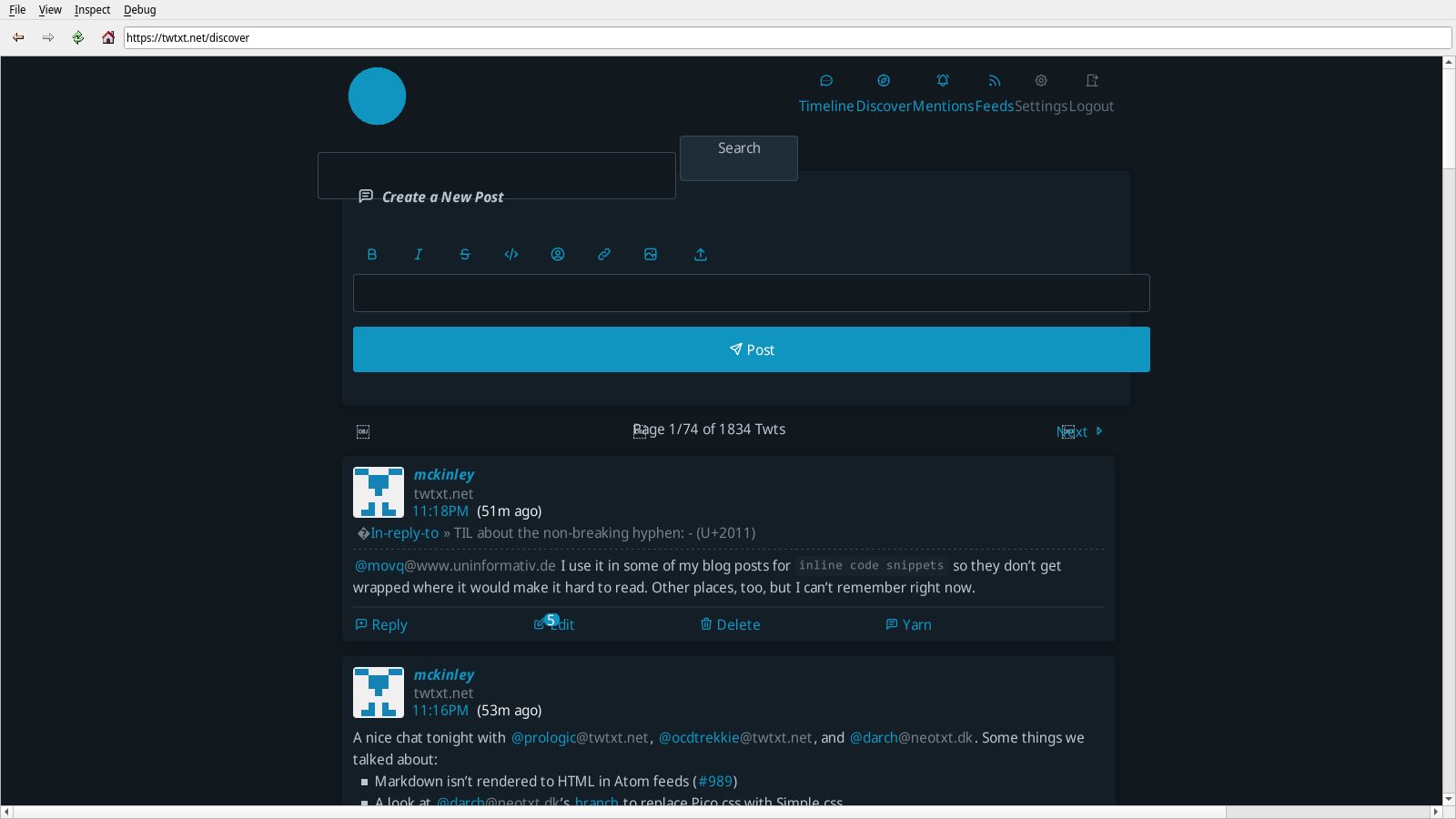
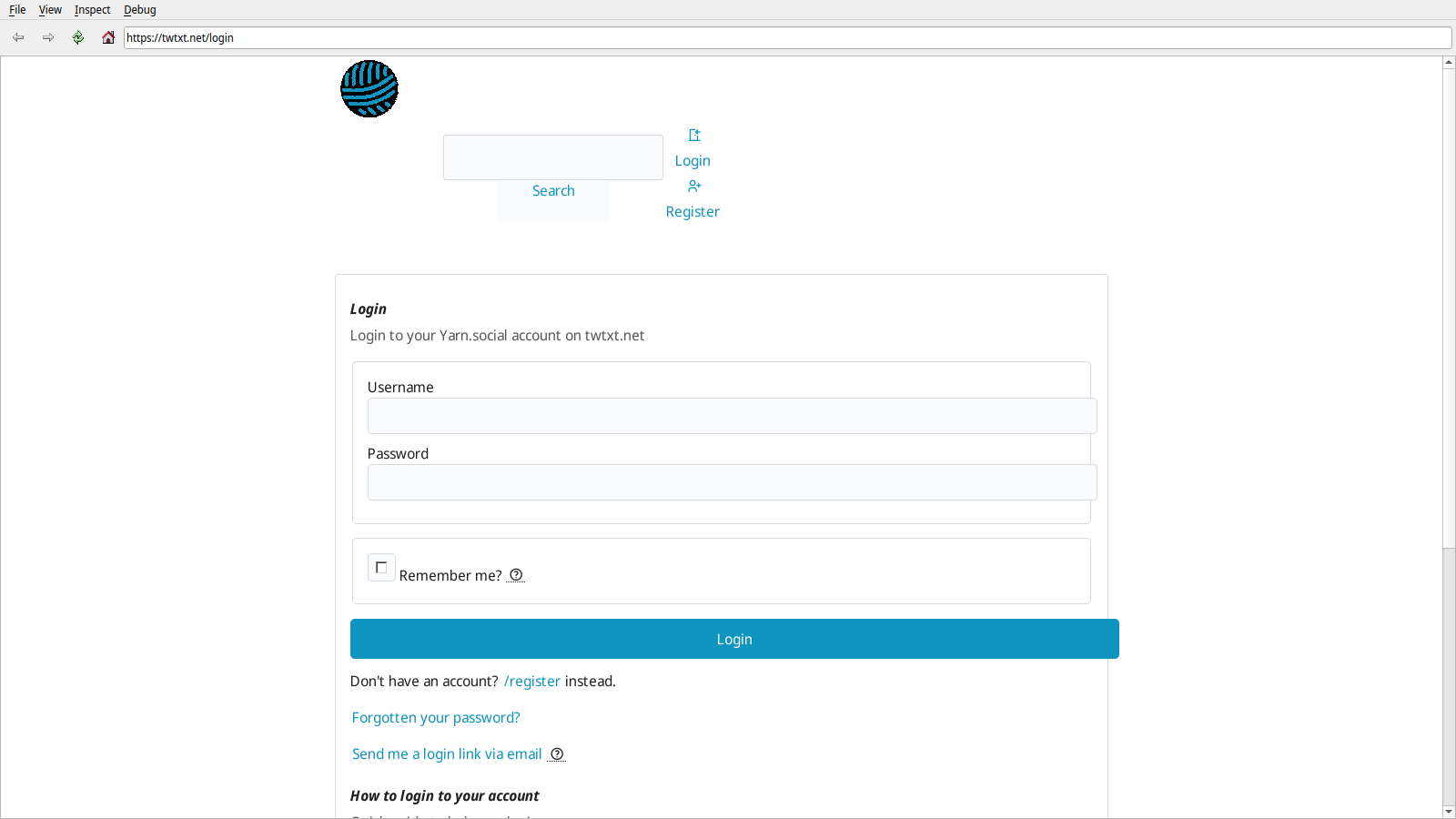
Some incremental progress has been made in text rendering. Both of these are better demonstrated on the login page [PNG, 26KiB].
{kind=link}
- Text is now rendered at the proper font size.
- Bold text is no longer erroneously rendered as bold + italic.
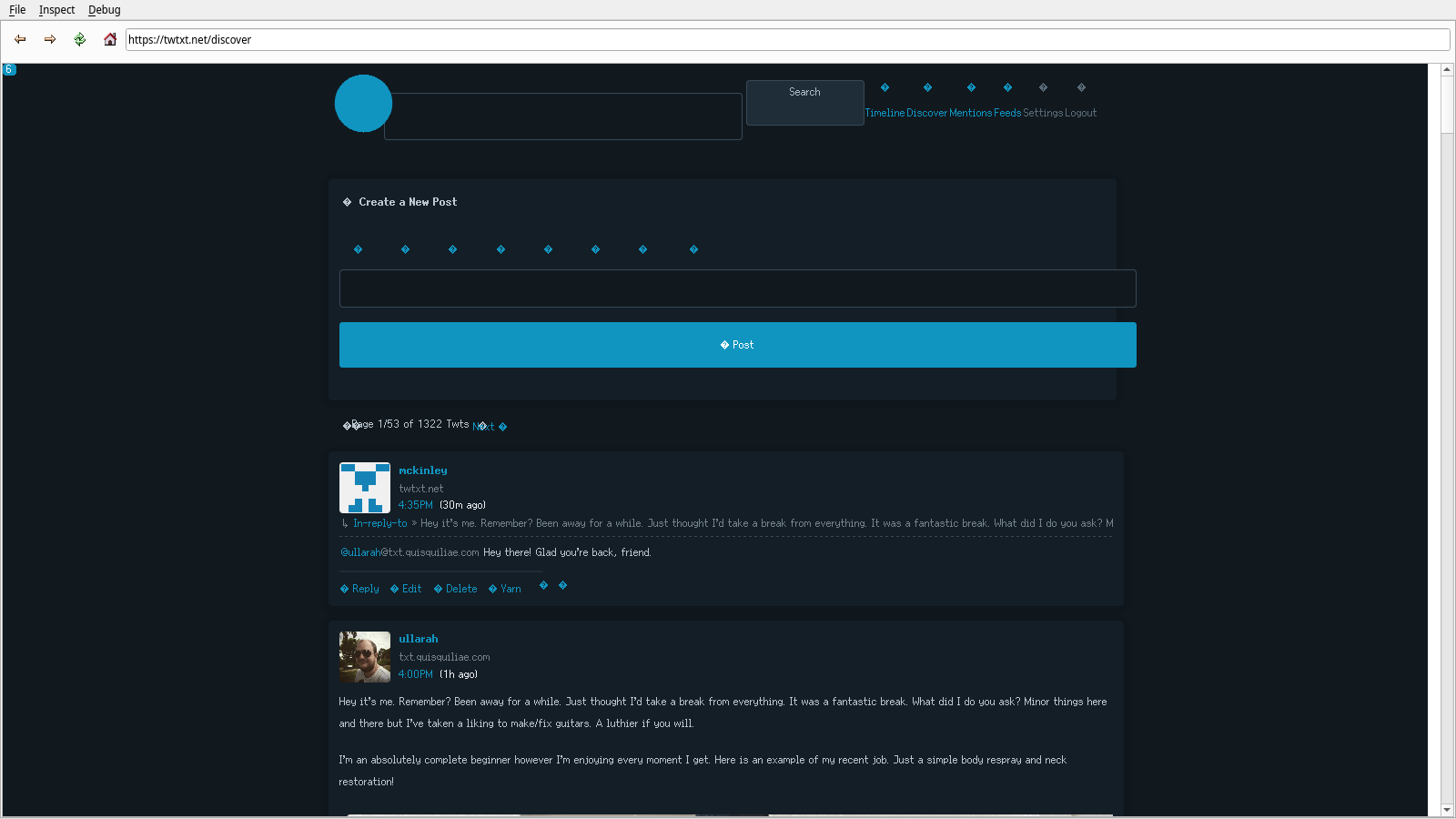
It is still impossible to post from Ladybird as textarea elements are still broken.
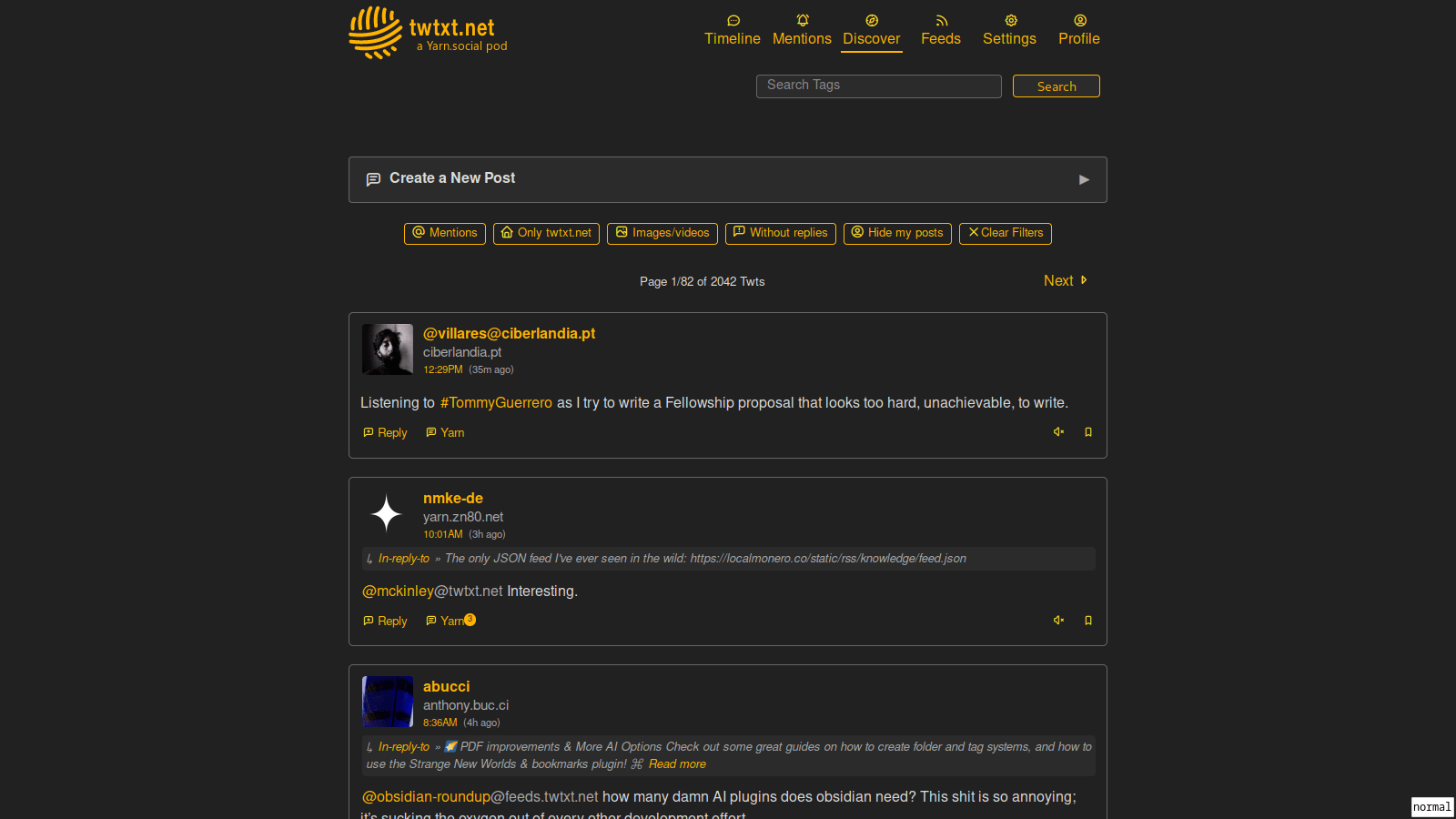
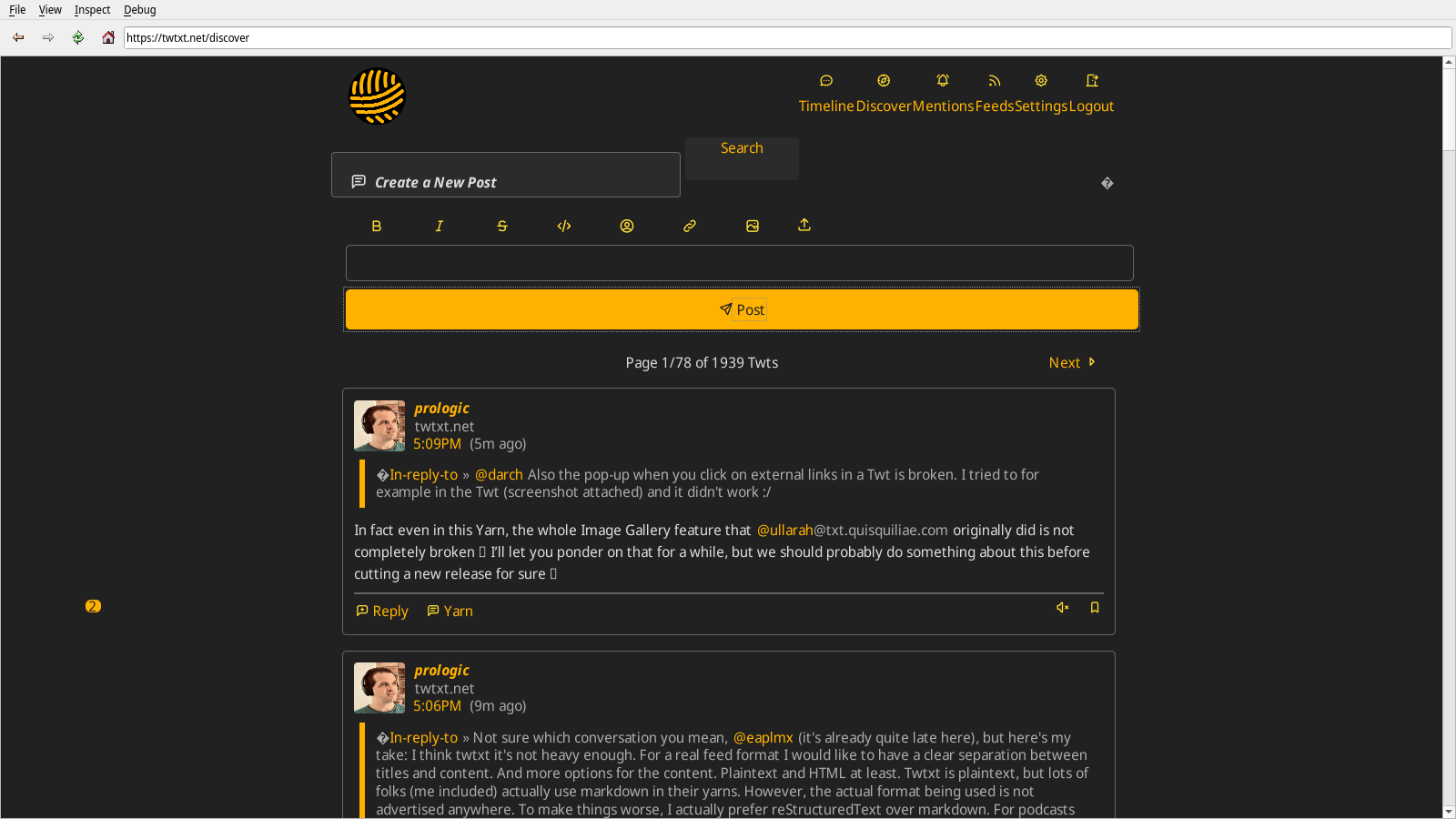
Here [PNG, 44KiB] is a reference image taked today in LibreWolf 112.0.2, and you'll find all the past screenshots below.
{kind=link}
- 2022-07-22 [PNG, 20KiB]
- 2022-09-15 [PNG, 22KiB]
- 2022-09-24 [PNG, 37KiB]
- 2022-09-24 after the big CSS update [PNG, 48KiB]
- 2022-11-19 [PNG, 26KiB]
- 2022-11-19, scrolled down [PNG, 47KiB]
- 2022-11-19 login page [PNG, 19KiB]
- 2022-11-19 reference image [PNG, 55KiB]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
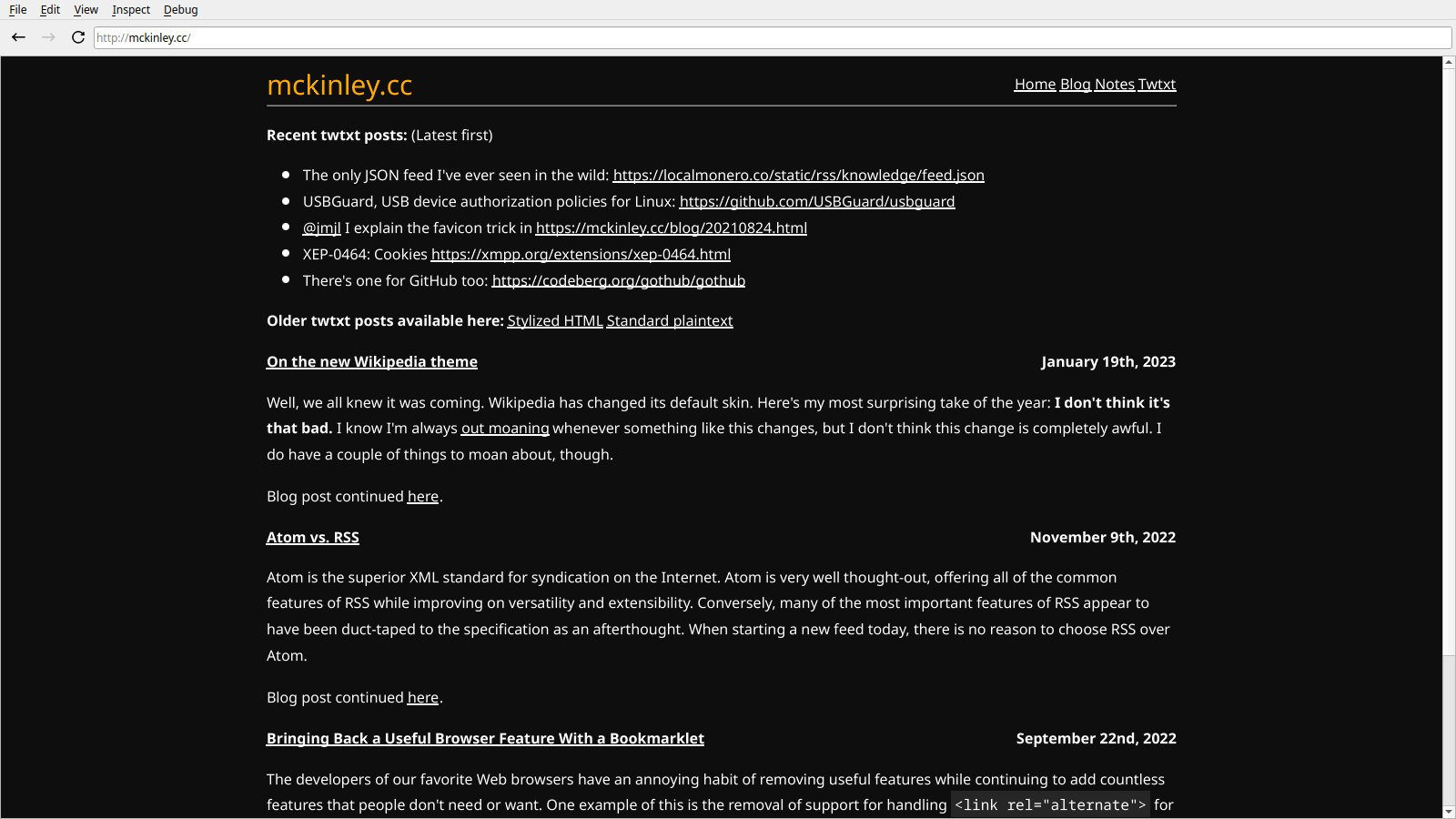
I'd also like to mention that the aforementioned font rendering improvements have made my website render perfectly. Here [PNG, 71KiB] is what it looks like. Look how far we've come [PNG, 19KiB] since 2022-07-22.
{kind=link}
{kind=link}